1. Qteasy Finanzhistorisches Datenmanagement
„qteasy“ ist ein umfassendes Toolkit für den quantitativen Handel, und die Erfassung und Nutzung von Finanzdaten ist eine der Kernfunktionen von „qteasy“.
1.1. Überblick
Derzeit gibt es viele verschiedene Online-Kanäle zum Erhalten von Finanzdaten, die es quantitativen Händlern ermöglichen, Finanzdaten herunterzuladen. Das Herunterladen von Daten direkt aus dem Internet hat jedoch mehrere Nachteile:
Inkonsistente Datenformate: Für dieselben Daten, z. B. Handelsvolumendaten, stellen einige Kanäle die Daten in „Lots“ bereit, während andere die Daten in „Anteilen“ bereitstellen.
Die Datenmenge, die extrahiert werden kann, ist begrenzt: Insbesondere Daten, die durch Web Scraping gewonnen werden, enthalten Hochfrequenz-Candlestick-Daten oft nur Daten der letzten Tage, und Daten aus früheren Zeiträumen sind nicht verfügbar.
Die Datenextraktion ist instabil: Geschwindigkeit und Erfolgsrate der Datenextraktion können nicht garantiert werden und werden stark von der Netzwerkkonnektivität beeinflusst.
Die Download-Kosten sind hoch: Bezahlte Datenkanäle liefern oft umfassendere Daten, unterliegen aber in der Regel Traffic-Beschränkungen, während kostenlose Kanäle unvollständige Daten anbieten, was ebenfalls die Kosten erhöht.
Die Informationsextraktion ist nicht einfach: Nach Erhalt der Rohdaten ist es notwendig, die Daten weiter in die erforderlichen Informationen umzuwandeln, ein Prozess, der mühsam und nicht intuitiv ist.
„qteasy“ wurde entwickelt, um die oben genannten Schwachstellen zu beheben.
Das Finanzdatenverwaltungsmodul von „qteasy“ bietet drei Hauptfunktionen, die alle mit dem Ziel entwickelt wurden, …
Datenabruf: Ruft verschiedene Finanzdaten von mehreren Online-Datenanbietern ab, um unterschiedlichen Benutzergewohnheiten gerecht zu werden.
Die von „qteasy“ bereitgestellte Datenabruf-API bietet leistungsstarke parallele Multithread-Downloads, Daten-Chunking-Downloads, Download-Verkehrskontrolle und Fehlerverzögerungs-Wiederholungsfunktionen, um sich an verschiedene abnormale Verkehrsgrenzen verschiedener Datenanbieter anzupassen. Gleichzeitig kann die Datenabruf-API problemlos und automatisch regelmäßig Batch-Daten-Download-Aufgaben ausführen, sodass Sie sich keine Sorgen über das Fehlen hochfrequenter Daten machen müssen.
Datenbereinigung und -speicherung: Standardisieren und definieren Sie die lokale Datenspeicherung, bereinigen und organisieren Sie aus dem Netzwerk abgerufene Daten, bevor Sie sie in einer lokalen Datenbank speichern.
„qteasy“ definiert eine dedizierte „DataSource“-Klasse zum Speichern historischer Finanzdaten und definiert eine große Anzahl standardisierter Speichertabellen für historische Finanzdaten vor. Unabhängig von der Datenquelle werden die endgültig gespeicherten Daten immer bereinigt und in einem einheitlichen Format im „DataSource“ gespeichert, wodurch Diskrepanzen durch Daten aus unterschiedlichen Zeiträumen und Quellen vermieden und eine qualitativ hochwertige Datenspeicherung gewährleistet werden. Es bietet außerdem mehrere Speicher-Engines, um den Nutzungsgewohnheiten verschiedener Benutzer gerecht zu werden.
Extraktion und Verwendung von Informationen: Das System unterscheidet zwischen „Daten“ und „Informationen“ und bietet eine Schnittstelle zum Extrahieren wirklich aussagekräftiger Informationen aus Datentabellen, die eine direkte Verwendung in Handelsstrategien oder Datenanalysen ermöglichen.
Wir wissen, dass „Daten“ nicht dasselbe ist wie „Informationen“. Das einfache lokale Speichern einer Datentabelle bedeutet nicht, dass die darin enthaltenen Informationen sofort verwendet werden können. „qteasy“ definiert speziell die nutzbaren „Informationen“ in einer Datentabelle als „DataType“-Objekte auf standardisierte Weise und vereinfacht so den Datenzugriffsprozess und die Definition von Strategien. Die einheitliche API macht die Informationsbeschaffung direkter und benutzerfreundlicher.
Im Allgemeinen kann die Struktur des Datenerfassungsmoduls in „qteasy“ durch das folgende Diagramm dargestellt werden:
QTEASY Datenverwaltungsmodul: 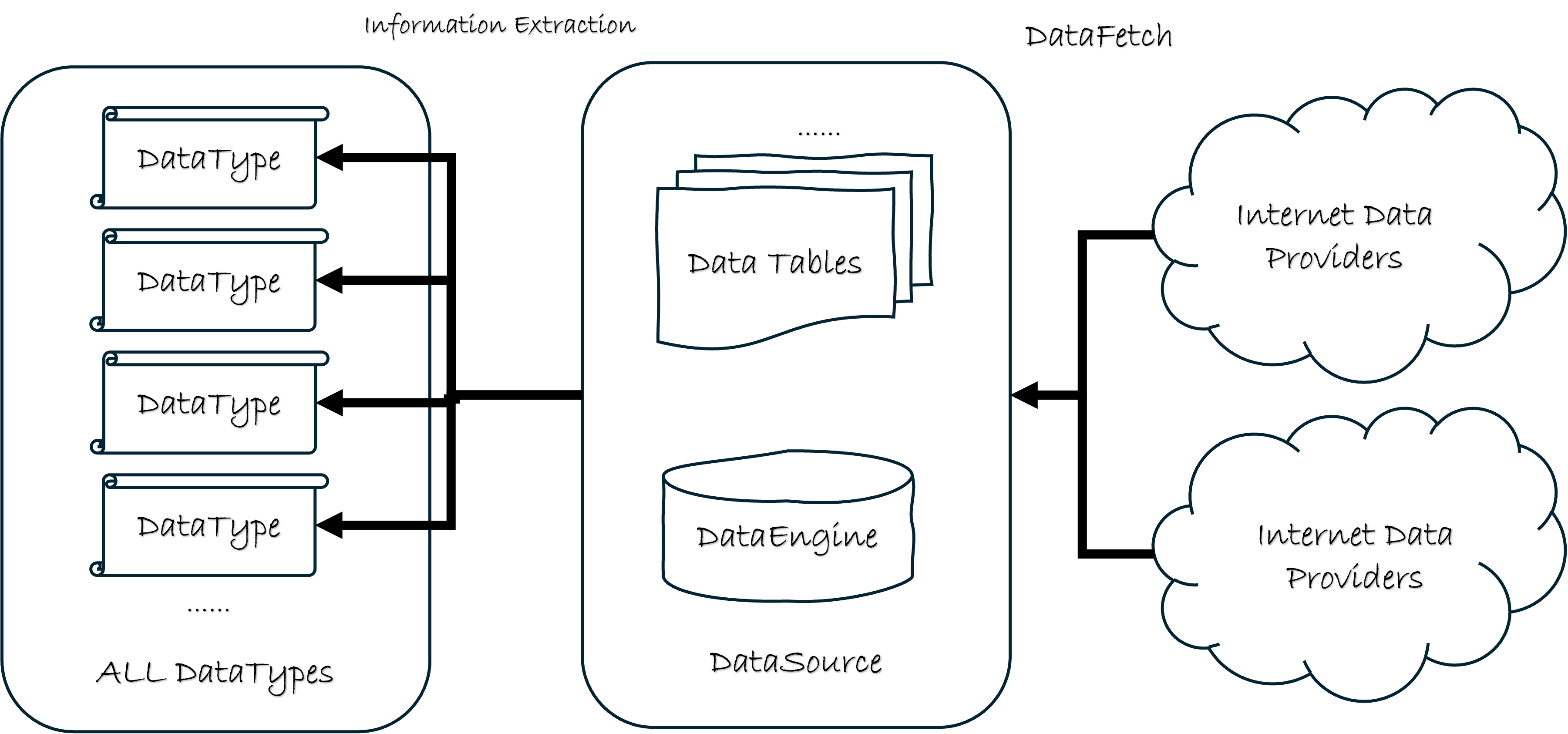
Wie im Diagramm gezeigt, ist die Datenfunktionalität von „qteasy“ in drei Schichten unterteilt. Die erste Schicht umfasst verschiedene Daten-Download-Schnittstellen zum Abrufen von Daten von Online-Datenanbietern; Dieser Vorgang wird „DataFetching“ genannt. Die zweite Schicht ist eine der Kernfunktionen von „qteasy“. Sie definiert eine lokale Datenbank zum Speichern einer großen Anzahl von Datentabellen und unterstützt mehrere Daten-Engines. Der Kern dieser Schicht ist die Klasse „DataSource“. Die dritte Schicht ist die Datenanwendungsschicht, die aussagekräftige Informationen aus den Datentabellen extrahiert und sie als „DataType“-Objekte definiert. Der Prozess der Datenextraktion wird als „Informationsextraktion“ bezeichnet. Dieses „DataType“-Objekt wird intern häufig in „qteasy“ verwendet. Die Erstellung von Handelsstrategien, die Durchführung von Datenanalysen, die Visualisierung und alle nachfolgenden Arbeiten basieren auf dem Objekt „DataType“.
正因为金融数据在量化交易过程中的重要性,从下一章节开始,我们将按以下顺序详细介绍 qteasy 数据功能的所有功能模块(阅读顺序与文件名编号一致,2 → 2.5 → 2.6 → 3 → … → 10):
2. DataType 对象与所有数据类型——信息与数据的区别、DataType 对象、所有内置数据类型清单
2.5. HistoryPanel(历史数据面板)——多标的、多指标、时间对齐的三维容器;与
get_history_data的配合及常用切片2.6. HistoryPanel 可视化——
HistoryPanel.plot()静态图与交互图、布局与可选依赖3. 本地数据源 DataSource——DataSource 对象与基本操作
4.~9. 内置数据表——各数据表的结构与用途
10. 数据拉取与渠道——从不同渠道拉取并填充数据